Data is dood: waarom de ‘data-driven enterprise’ er niet gaat komen
Wouter van Aerle, Managing Partner – februari 2023.
Na weer een ronkend verhaal over hoe de ‘data-driven enterprise’ er in 2025 uit gaat zien of de ‘Big Data Trends 2023’ ben ik er he-le-maal klaar mee. Het is luchtfietserij gebaseerd op wensdenken. Degenen die dagelijks met hun poten in de klei staan, weten wat ik bedoel. Ja, de data groeit alleen maar en ja, we hebben allemaal fantastische technologie, en ja de mogelijkheden zijn eindeloos maar daarmee gaat het nog niet lukken hè?
“By 2025, smart workflows and seamless interactions among humans and machines will likely be as standard as the corporate balance sheet, and most employees will use data to optimize nearly evry aspect of their work.”
Tuurlijk, sweet dreams. Normaal gesproken ben ik niet zo uitgesproken maar nu ga ik er even met gestrekt been in, compleet met HOOFDLETTERS om mijn punt te maken. Dit is waarom ik denk dat de data-driven enterprise er niet (ok, kleine nuance: op de huidige manier) gaat komen.
<rant>
1. Organisaties hebben hun data shit niet op orde
Met stip op één. Vrijwel zonder uitzondering kampt IEDERE organisatie met een gigantische data schuld (ref: @Ronald Damhof). Dit is op zich zelf al een enorm probleem waardoor de randvoorwaarden ontbreken om met data te innoveren of ‘slimme dingen te doen’.
In alle verhalen over AI, ML, analytics of data science ontbreekt ook maar enige realiteitszin over de werkelijke situatie rondom de datapositie van een organisatie. Alsof alle data netjes keurig georganiseerd, gemetadateerd, beschikbaar, voorzien van de juiste definities en van het juiste kwaliteitsniveau, opgestapeld in overzichtelijke Ikea Hyllis stellingkasten liggen te wachten om lekker geanalyseerd te worden.
Wake up and smell the coffee. Spreek een willekeurige data scientist in je organisatie aan en die zal je vertellen dat hij of zij 80% van zijn tijd bezig is metadata preparatie. Maar gelukkig doet hij dat wel hééél Agile!!
Niet alleen is dit een enorm randvoorwaardelijk probleem, ook ontbreekt het aan prioriteit, mensen en middelen om dit structureel op te lossen. Ik snap het, het is niet sexy om dit te doen en dit soort refactoring – als het al überhaupt gebeurt – vindt allemaal onder de motorkap plaats. Dus aan de buitenkant lijkt het net of er niks verandert. Maar het moet; alleen het gebeurt niet.
En dus blijven organisaties van oplossinkje naar oplossinkje hobbelen (“alles naar de cloud!”), waardoor een probleem of organisatievraagstuk op de korte termijn is opgelost en tegelijkertijd de data schuld alleen maar groter wordt.
“Maar het werkt toch?” hoor ik je dan vervolgens zeggen. Ja, het werkt, alleen hangt de gegevensverwerking met duck-tape aan elkaar, is deze niet schaalbaar, zit alles in het hoofd van die twee engineers in kamer 4.50 en draait de verificatie-module lokaal op iemands laptop. Hoezo Agile? “Maar de code staat wel netjes geversioneerd in Git.” zei iemand vorige week tegen me.
[..neemt even een slokje water…]
Hoe ‘goed’ dit werkt wordt duidelijk als er een wijziging moet worden doorgevoerd of alle data van één bepaalde relatie naar boven gehaald moet worden. Hoezo flexibel? En NEEEEE: dat komt NIET door de technologie die je in huis hebt, zie punt 3.
Een vraag over de herkomst van een bepaald gegeven of waar de gegevens van een specifiek persoon staan, leggen vaak feilloos de onvolkomenheden bloot in de gegevenshuishouding
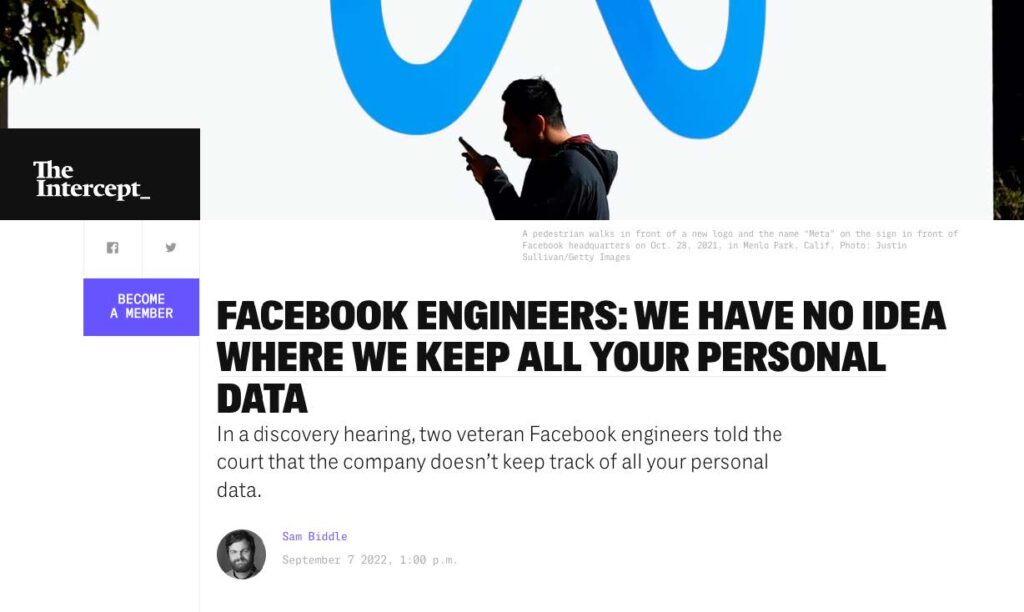
HET…IS…EEN…ZOOITJE.
2. Hoger onderwijs levert de verkeerde professionals af
Zo, laat de comments maar komen want hier vinden vast een heleboel mensen iets van.
De afgelopen jaren hebben hogescholen en universiteiten massaal geïnvesteerd in data opleidingen. Bachelors, Masters en post-graduate opleidingen: over de hele linie zijn dit soort opleidingen als paddenstoelen uit de grond geschoten.
Maar laten we even precies zijn: het gaat om data ANALYTICS en data SCIENCE-opleidingen. De primaire focus in al deze opleidingen is het GEBRUIK van data. NIET, hoe de data tot stand komt of beheerd zou moeten worden. Dat is nogal een verschil.
Pak een willekeurig curriculum en het gros van de vakken heeft betrekking op programmeren (Python, R etc), analytische technieken (ML, calculus, lineaire algebra, statistiek) en nog wat andere vakken (vaak ethiek en privacy). En als je mazzel hebt, ergens een half dagje datamanagement & data governance.
Maar dit zijn NIET de kennis en vaardigheden die nodig zijn om de data schuld op te ruimen en deze in de toekomst verder te voorkomen. Kennis- en informatiemodellering, gegevenstypering, systeemtheorie, kwaliteitsleer, (predicaten)logica & verzamelingenleer, tijd in databases, semantiek etc. Cruciale kennis en vaardigheden waarvan delen niet of nauwelijks (laat staan in samenhang) meer worden gedoceerd aan het hoger onderwijs. Met gemak kan ik zo een heel curriculum voor een Bachelor- en Masters-opleiding opschrijven.
We hebben dus een dubbel probleem: een enorme data schuld EN een afnemende instroom van nieuwe gekwalificeerde mensen die deze problemen kunnen oplossen.
Maar het probleem is NOG groter. Want ook toekomstige managers en bestuurders wordt NIET geleerd wat er nodig is. Kijk naar het curriculum van bijvoorbeeld MBA-opleidingen: vakken op het gebied van Finance (heel veel vakken), Legal, HR, Strategy, Entrepreneurship en oh ja: Digital (lees: tech). Met als gevolg dat de nieuwe instroom van managers en bestuurders ook niet weten wat er nodig. Ja, ze zijn steeds meer ‘tech savvy’ en dit leidt tot nieuwe businessmodellen en proposities maar ook daar is data voor nodig hè?
De vraag of een organisatie ‘datagedreven’ (whatever dat in vredesnaam is) moet worden, is totaal niet relevant. De wereld digitaliseert en dataficeert in een moordend tempo. Of je nu wel of niet een ‘analytics competitor’ of ‘slimme dingen met data’ wilt doen; die data is er gewoon in je organisatie. En daar heb je gewoon voor te zorgen. Net als dat je mensen en financiële middelen nodig hebt om een organisatie te ‘draaien’, heb je ook data nodig. Organisaties kunnen het zich niet veroorloven om dat niet te beheersen. Voor mensen (HR) en financiële middelen (Finance) is dat volledig geïnstitutionaliseerd. Iedereen begrijpt dat je deze functies moet inrichten want anders kun je je organisatie niet draaiend houden. Het is de ‘cost of doing business’. Niemand zal vragen naar de businesscase voor de Finance of HR-functie.
Dat is voor data niet anders. Organisaties kunnen het zich niet meer veroorloven dit niet te managen. Met andere woorden: het inrichten en beheersen van de gegevenshuishouding moet een organisatorische vaardigheid worden, net als Finance en HR dat zijn. DAT is wat de manager in spé moet worden aangeleerd op Harvard.
3. Technologie is het probleem, niet de oplossing
Werkelijk iedereen – leveranciers voorop – roepen allemaal in koor dat technologie niet de oplossing is en toch is dat wat vrijwel iedere organisatie als eerste doet: “Is er een tool voor?”. Of de grootste dooddoener: “Wat heeft Microsoft?”, want de organisatie heeft een Microsoft-tenzij beleid. HELP!!! Om deze reden investeren organisaties soms kostbare tijd om erachter te komen dat Azure Purview echt een heel erg *** product is, maar ‘promising roadmap’ en de features die nodig zijn, zijn ‘planned for the spring release’. Dus we sukkelen nog maar even verder.
“<Vendor X> is excellent at touting a roadmap for their products that never seem to materialize… at least in the timeframe they promise.” — LinkedIn Group discussie
Meer of andere technologie naar binnen fietsen in een gegevenslandschap dat ‘één grote geitenbak’ is (dixit @Roy Maassen), is vragen om problemen. Technologie zijn bakstenen, maar wat je nodig hebt is een nieuw gebouw of een renovatie. En dus is er een ontwerp en architectuur nodig. En dat vereist diepgaande kennis van de data, hoe gegevensstromen lopen en hoe data applicatief gebruikt wordt. Het ontbreekt vaak aan de rust en bereidheid om dat voldoende inzichtelijk te maken.
“Maar dat duurt zo lang…..”. Inderdaad, dat komt omdat het AL een zooitje is en organisaties die gifbeker maar niet (willen) leegdrinken. En dus plakken we er maar weer een technologie aan vast. Uit eerste hand ken ik voorbeelden waar werkelijk tientallen miljoenen euro’s zijn verbrand om een data-lake neer te zetten (“want het data warehouse was echt wel legacy geworden”) om erachter te komen dat er niets mee is opgelost. Maar gelukkig is er nu wel een ‘modern datastack’.
Verwacht ook niet dat de industrie hier met een oplossing gaat komen. Die heeft er alleen belang bij om steeds nieuwe licenties of producten te verkopen; niet om jouw data shit op te ruimen (alle leveranciers nu boos…). Waar technologie voor nodig is, is om de vakgebieden te ondersteunen die écht nodig zijn zoals modellering of de omgang met tijd en correcties in het verleden (zie punt 2 hierboven). De verhoudingen in de markt qua aanbod van technologie zijn volkomen disproportioneel. Het aantal verschillende database platformen (ooit gehoord van Yugabyte?) is niet meer bij te houden, maar fatsoenlijke modelleersoftware in de cloud kan de markt niet bieden.
Tuurlijk, technologie lost een hoop op. Vroegûh moest je geheugenkaarten kopen waar je 3 maanden op moest wachten alvorens ze in de server te douwen; nu klikje in de cloud even 16Gb geheugen erbij.

(Copyright: Office Space)
Helaas is de keerzijde van snelle technologische innovaties dat veel (bewezen) ontwerp- en architectuurpatronen rücksichtlos bij het oud vuil worden gezet. Of nog preciezer: architectuur- en ontwerpactiviteiten worden bij het oud vuil gezet. Door de nadruk die Agile & DevOps op ‘coderen, coderen, coderen’ leggen (vrij naar Daniel Koerhuis), is de heilige graal bij het realiseren van oplossingen, zo hard en zo veel mogelijk rammen op een toetsenbord. De tijd die organisaties willen c.q. moeten nemen om goed na te denken WAT ze willen, WAAROM en HOE dat zou moeten werken, verschuift steeds meer naar (nog meer) programmeertijd. De fundamentele fout die hierbij wordt gemaakt is dat het realiseren van een datapositie of integrale, samenhangende gegevenshuishouding infrastructureel van aard is. De ene technologie vervangen door de andere zodat je nog harder en sneller op je toetsenbord kan rammen werkt dan eerder averechts.
4. Je bent geen Spotify, Booking of Adyen
Organisaties nemen vaak andere – vaak jongere, innovatievere, – organisaties als voorbeeld hoe ze het anders willen. Onder het mom van, als je niet verandert, ben je over vijf jaar out-of-business, worden grootse vergezichten getekend en dito veranderprogramma’s opgezet. Maar wat vaak onderbelicht blijft, is de enorme veranderopgave die dit met zich meebrengt en wat het écht vraagt van een organisatie.
Ik heb het van dichtbij mee mogen maken hoe een, relatief jonge (ca. 20 jaar oude) organisatie (tussen de 500-1.000 medewerkers), al jaren bezig is om datagedreven te worden. Dit doen ze naar mijn mening volgens het boekje, met alle aandacht voor organisatieverandering (eigenaarschap directie, opleiding &training, cultuurverandering, nieuwe functies , reorganisaties etc). Het…is…fucking….moeilijk.
Wil je écht een datagedreven organisatie worden, dan moet een organisatie bereid zijn haar bestaande business model overboord te gooien, te kannibaliseren op bestaande verdienmodellen. manieren van werken diametraal te veranderen of haar hele personeelsbestand te vernieuwen. Ok, ik overdrijf misschien een beetje maar dit is wat echte verandering betekent. Het er een beetje bij doen – of nog erger: naast elkaar – gaat ‘m niet worden.
OF het voor een organisatie nodig is de nieuwe Spotify te worden, is allereerst een strategisch vraagstuk, niet een data-vraagstuk (zie ook punt 5). Maar gestel dat die afweging is gemaakt, dan is het onvermijdelijk om het verandermonster in de bek te kijken. Alleen dan maakt de gewenste transitie enige kans van slagen. Met het aannemen van 10 data scientists, het opzetten van een Data lab en aanschaffen van Databricks ga je er echt niet komen (tenzij precies dat je doel was… #wink).
5. Data is een middel, geen doel
We komen in de situatie terecht, of zijn daar misschien al lang in beland, dat het gebruik van data een doel op zich is geworden, in plaats van een middel. De hele gedachte van ‘slimme dingen doen met data’ brengt met zich mee dat data als een hamer wordt gezien en ieder probleem of kans als een spijker. Dit leidt enorm de aandacht af van werkelijke problemen of maatschappelijke vraagstukken die spelen.
Zo sprak iemand van een grote gemeente onlangs over de problematiek van zwervers en daklozen in de stad. “Zou het niet mooi zijn als we daar allemaal data van hebben?”. Qua statistiek misschien ja, maar niet – zoals het werd bedoeld – om dit vraagstuk operationeel aan te pakken. Please! Een wijkagent of BOA die al in de wijk is en vaak iedere hoek van de straat kent is toch veel effectiever? En een snellere en gemakkelijker informatiebron?
Niet iedere organisatie hoeft een datagedreven-organisatie te worden, los van de vraag wat onder zo’n kwalificatie moet worden verstaan. Het belang van gegevens in een organisatie loopt immers sterk uiteen. Er valt een heel spectrum te tekenen tussen enerzijds organisaties waar het primaire product of dienst gegevens zelf zijn (commerciële data providers bijvoorbeeld) en anderzijds organisaties waar gegevens hooguit ondersteunend zijn.
Eerder werd al aangegeven dat gegevens in vrijwel iedere organisatie voorkomen. Het beheren van deze gegevens is daarom hoe dan ook nodig. Maar het feit dat die gegevens er zijn, betekent vervolgens niet automatisch dat het hele bedrijfsmodel dan maar overhoop gehaald moet worden om ‘data driven’ te worden. Het doet een beetje denken aan de jaren 2000 toen organisaties zenuwachtig werden als ze geen data warehouse hadden. “Wij gaan ook een data warehouse bouwen! Waarom? Omdat onze concurrenten dat ook doen!”.
Om werkelijk te kunnen beoordelen hoe een organisatie data als middel in kan zetten, is inzicht nodig in de eigen bedrijfsvoering, strategie en hieraan gerelateerde doelstellingen. Dit lijkt vanzelfsprekend maar ik heb meerdere keren ervaren dat dit geenszins het geval is. En als dat inzicht er al is, moet er ook naar gehandeld worden. Hierin schuilt een grote blinde vlek voor veel organisaties. Want om de werkelijke bijdrage van data te kunnen beoordelen, is inzicht nodig in hoe processen nu lopen, waarom wordt gewerkt zoals een organisatie werkt en hoe bepaalde inrichting tot stand is gekomen.
Immers, vanuit dat inzicht kan ook de bijdrage van gegevens onderbouwd worden. De harde realiteit is dat organisaties het antwoord op dat soort – bijna existentiële vragen – niet kennen of onder ogen willen zien. Want het eerlijke antwoord is dat ze soms niet weten wat ze doen of hoe ze werken. Dat erkennen legt een gevoelige kwetsbaarheid bloot.
Dus worden dat soort reflecties zorgvuldig vermeden en de aandacht gevestigd op de Data Shop want daar kan iedereen nu gemakkelijk zelf zijn data vinden…
Het wordt tijd dat organisaties weer met beide benen op de grond komen te staan, zeker omdat de volgende trend (ChatGPT anyone?) zich alweer aan dient. Waartoe zijn we als organisatie op aarde? Wat zijn onze kernwaarden? Wat is onze waardepropositie of taak? Voor wie doen we dit? Pas als dat soort vragen specifiek en eenduidig beantwoord kunnen worden, is het nuttig om eens naar die data dingetjes te gaan kijken.
En nu?
Mooi verhaal, Van Aerle. En hoe nu verder? Tja, goede vraag. Daar heb ik zeker een ander blog (en wel meer) voor nodig. Maar het zou al een stap vooruit zijn als er meer herkenning en erkenning is voor de situatie waarin het vakgebied en de markt zich nu bevindt. Minder focus op technologie, realiteitszin en strategisch denken en onderkennen dat gegevensmanagement gewoon werk is wat structurele inrichting vergt. Als we daarin vooruitgang weten te boeken, dan komt die data-driven enterprise er echt wel.

</rant>.
McKinsey Digital. (2022). The data-driven enterprise of 2025 [white-paper].
Biddle, S. (2022, September 7). Facebook Engineers: we have no idea where we keep all your personal data. The Intercept
.