Meerwaarde van een data management metamodel
In eerdere posts hebben we het belang van een metamodel beschreven. Een goed ontworpen metamodel creëert eenheid van taal om over data en datamanagement te communiceren en ondersteunt het administreren van relevante metadata. Hiermee wordt een belangrijke randvoorwaarde voor effectief data management ingevuld. Ieder data management initiatief begint immers met inzicht in die data die je wil beheersen.
Een begrijpelijke vraag is dan waar te beginnen. Hoe ziet zo’n metamodel eruit? Wat moet er wel en niet in zitten? Dat beschrijven we in dit artikel (en ja: we lichten ook toe waar die afwasborstels en lollies vandaag komen).
Basis van het metamodel is de data zelf
Zoals we verderop laten zien, begint ieder metamodel met een representatie van de data zelf. In ons werk gebruiken we hiertoe drie kernconcepten die het hart van ieder metamodel vormen. Wanneer deze basis eenmaal staat, is het relatief eenvoudig om het model uit te breiden en andere data management concepten (bijvoorbeeld dataclassificaties, kwaliteitseisen, toegangsregels of verantwoordelijkheden) toe te voegen aan het model.
Voordat we ons metamodel toelichten, beschrijven we eerst een aantal overwegingen die ten grondslag liggen aan de opzet ervan. Aan het einde van dit artikel geven we een aantal handvatten hoe je het basis metamodel in je eigen organisatie kunt toepassen.
Overwegingen en verantwoording
Voor de opzet van het metamodel hebben we dankbaar gebruik gemaakt van het werk van Van der Sanden & Sturm (1996). De uitgangspunten en principes uit dit boek hebben we verwerkt in onze opzet. Om te begrijpen waarom het metamodel is opgezet zoals het is opgezet, bespreken we daarom eerst de belangrijkste uitgangspunten die mede ontleend zijn aan hun werk.
Zelfstandige beschouwing van data
Centraal staat de aanname dat een groot deel van de gegevens toegankelijk moet zijn voor ander gebruik dan waarvoor ze oorspronkelijk zijn verzameld. Dit vereist een zelfstandig beheer van gegevens, ontkoppeld van het gebruik van diezelfde data. Vertaald naar metadata management en een metamodel, betekent dit dus dat er een beschouwingswijze van data nodig is, die in beginsel los staat van het gebruik van die data. Dit veronderstelt daarmee ook een mate van ontkoppeling tussen applicaties of systemen en data. In de taal en de concepten waarmee we over data communiceren moeten we dus zien los te komen van het applicatie- of systeemdenken.
Communicatie over data los van systemen en applicaties
Die ontkoppeling is er in de praktijk natuurlijk lang niet altijd. Voor de implementatie van datamanagement maatregelen kan dit dus praktische consequenties hebben. Het is wat ons betreft echter geen reden om deze benadering niet te hanteren. Het helpt juist om inzichtelijk te maken waarom het soms knelt en wat er nodig is om dat te doorbreken. Verderop zullen we laten zien hoe het metamodel kan helpen concepten met betrekking tot ‘data’ en ‘systemen’ zowel afzonderlijk als in samenhang te beschouwen.
Abstracte en concrete beschouwing van data
Een hele gegevenshuishouding is te omvangrijk en/of te gecompliceerd om als geheel te beheren of te veranderen. Het is daarom nodig om de gegevenshuishouding op te splitsen in aandachtsgebieden waarvan de ontwikkeling en beheer relatief onafhankelijk kan plaatsvinden.
Communiceer op het juiste detailniveau over data
Om die opdeling te kunnen maken, moet een metamodel ook in een beschouwingswijze voorzien die het mogelijk maakt om over de data te kunnen praten, zonder dat we meteen in veel details (van de data zelf) belanden. Kolommen, velden, tabellen of files bijvoorbeeld zijn herkenbaar (en concreet) maar vaak – niet altijd, afhankelijk van het concern dat je wilt managen! – zo gedetailleerd dat het een effectief gebruik in de weg staat. Het inzichtelijk maken welke data bijvoorbeeld gebruikt wordt door een bedrijfsproces door het opsommen van alle losse attributen, zal waarschijnlijk al snel het overzicht bemoeilijken. Een hoger abstractieniveau om aan data te kunnen refereren is dan nodig.
Een metamodel helpt om het data landschap zinvol op te splitsen en om tegelijkertijd op een abstract en concreet c.q. detail-niveau over data te praten en bijbehorende metadata hierover vast te leggen.
Deltiq Datamanagement Metamodel
Het metamodel dat we hieronder uiteenzetten geeft een invulling aan de hierboven genoemde concerns. Het is ondertussen in meerdere organisaties toegepast en steeds verder aangescherpt. Die ervaring laat zien dat het helpt om op een gestructureerde manier metadata vast te leggen en stapsgewijs meer metadata aan het model toe te voegen zonder de samenhang uit het oog te verliezen. Een vraag die meteen opkomt is natuurlijk of dit het enige of beste model is. Maar waar het feitelijk om gaat is de vraag of het nuttig is. Of zoals ze in de Design Science benadering (ref. [2]) zeggen: Does it work? Wij ervaren vooralsnog van wel.
Drie kernconcepten
Het metamodel kent drie kernconcepten: Gegevensgebied, Gegevensverzameling en Gegevensmiddel. Zie de figuur hieronder.
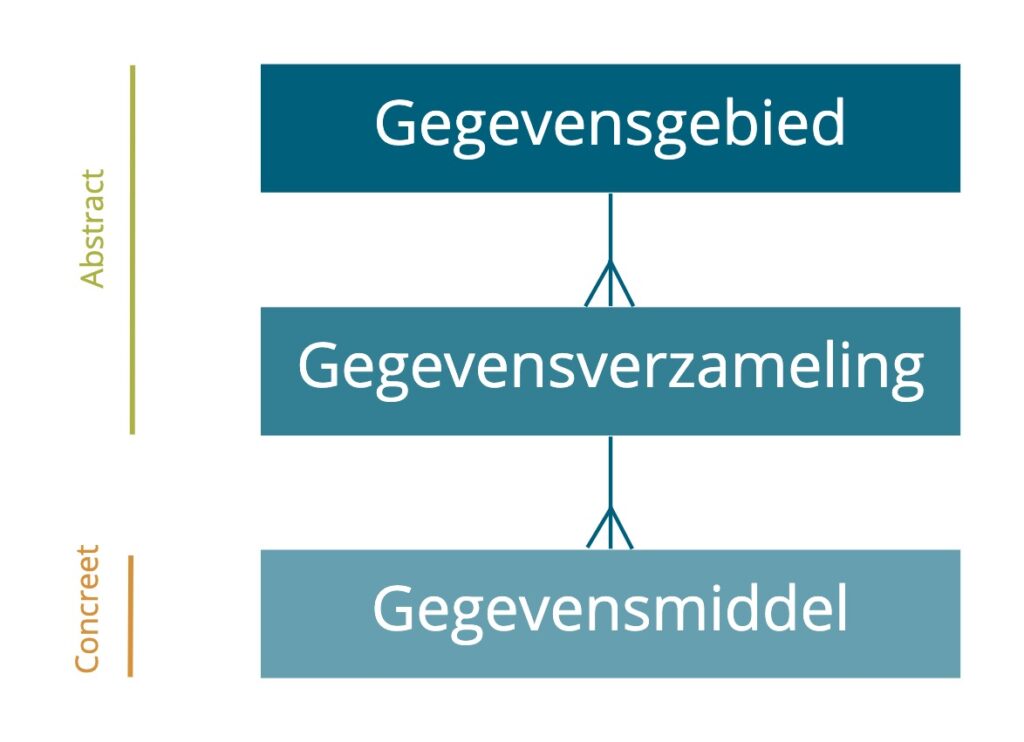
Zoals in het model is weergegeven, is er sprake van zowel een abstract als concreet niveau. Gegevensmiddelen representeren concrete, fysieke gegevensdragers. Gegevensgebieden en -verzamelingen zijn abstracte concepten. Ieder van de concepten wordt hieronder nader toegelicht.
Voorbehoud
We volstaan hier met een globale beschrijving van het metamodel. Het model en de toepassing ervan kent diverse nuances die te ver voeren om hier te behandelen. Zo beperken we ons hier tot een globale definitie van ieder concept. Ook specifieke business rules die van toepassing zijn laten we achterwege. We maken met voorbeelden duidelijk hoe de concepten werken. Vanzelfsprekend zal deze operationalisatie van de betreffende concepten voor iedere organisatie in praktijk weer anders zijn.
Gegevensgebied
Een gegevensgebied representeert gegevens (of preciezer: gegevenstypen) die uit het oogpunt van beheer sterk samenhangen. Gegevens binnen een gegevensgebied hebben een sterke interne samenhang en zwakke koppeling met gegevens in een ander gegevensgebied.
Organisatieonafhankelijke indeling van gegevens
De nadruk op beheer is essentieel. Verschillende gegevens – d.w.z. gegevens uit verschillende gegevensgebieden – worden vanuit het oogpunt van gebruik gecombineerd ten behoeve van een specifiek bedrijfsproces of applicatie. Die combinatie is iedere keer weer anders, afhankelijk van het gebruik c.q. toepassing. Hiermee wordt ook duidelijk dat de indeling van gegevensgebieden ook organisatieonafhankelijk hoort te zijn.
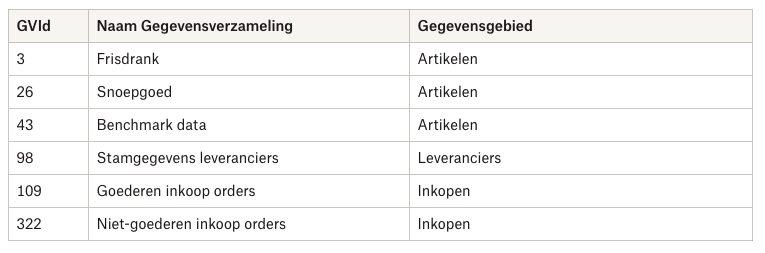
Gegevensgebieden vormen het hoogste abstractieniveau om data te beschouwen. Neem een retailorganisatie. Typische gegevensgebieden zouden bijvoorbeeld kunnen zijn: Klanten, Artikelen, Winkels, Voorraad, Verkopen, Schapruimte, Goederenbewegingen, Leveranciers, Inkopen etc. Als vuistregel kun je aanhouden dat er vaak sprake is van zo’n 10 – 30 gegevensgebieden binnen een organisatie.
Duidelijk is dat op het niveau van Gegevensgebieden fysieke implementatie c.q. representatie van die data geen concern is. De data(waarden) over Artikelen bijvoorbeeld kunnen vastliggen in een XML-bestand dat dagelijks wordt verstrekt door een leverancier. Maar ook in een interne artikelen-database. Die technische eigenschappen zijn echter niet relevant op het niveau van een Gegevensgebied.
Gegevensverzameling
Gegevens binnen één gegevensgebied kunnen worden opgedeeld in deelpopulaties: de gegevensverzamelingen. In beginsel bevat iedere gegevensverzameling dezelfde type gegevens. Maar deze kunnen in specifieke gevallen per gegevensverzameling ook verschillen, bijvoorbeeld wanneer het nuttig is om vanuit beheer oogpunt onderscheid te maken naar verschillende gegevenstypen: afdeling A doet bijvoorbeeld data entry voor bepaalde gegevenstypen (lees: velden, attributen, kolommen); afdeling B verrijkt dat met aanvullende gegevenstypen.
Terug naar het voorbeeld van het gegevensgebied Artikelen. Binnen een grote retailorganisatie kan het al snel om duizenden artikelen (‘records’) gaan. Aannemend dat de gegevenstypen voor ieder artikel hetzelfde zijn (ieder artikel kent bijvoorbeeld een naam, afmeting, EAN-code, kleur) zijn de gegevenswaarden dat vanzelfsprekend niet. Een afwasborstel is wat anders dan een zak Chupa Chup lollies.
Wie is er verantwoordelijk voor de lolly’s en wie voor de afwasborstels?
Kwalitatief goede artikelgegevens zijn essentieel voor een retailorganisatie: ze worden gebruikt om te beslissen hoeveel artikelen in één keer in een krat of rolcontainer passen, zijn bepalend voor hoeveel stuks in een winkelschap kunnen, worden gebruikt bij het afrekenen etc. Om de kwaliteit te kunnen beheersen, is het vanuit data management-perspectief logisch om verantwoordelijkheden hiervoor te beleggen. Maar aan welke (beschouwing van de) artikeldata wijs je die verantwoordelijkheid toe? Dat kan op het niveau van het hele gegevensgebied (en daarmee alle artikeldata: één functionaris krijgt dan de verantwoordelijkheid over de kwaliteit van alle gegevens) maar kan praktisch gezien tot belemmeringen in de uitvoering leiden. Een alternatief is om deze verantwoordelijkheid op het niveau van de onderliggende gegevensverzamelingen te leggen. Stel dat er artikelgroepen worden onderkend als Schoonmaak-artikelen, Snoepgoed, Frisdranken etc. Grote kans dat er binnen de organisatie bijvoorbeeld dan ook productmanagers zijn die verantwoordelijk zijn voor een deel van het assortiment. Daar ook de verantwoordelijkheid beleggen voor de data over die artikelen is dan niet onlogisch.
Onderverdeling in verzamelingen helpt bij het beheer ervan
Gegevensverzamelingen zijn zo een krachtig instrument om langs verschillende typeringen of concerns een Gegevensgebied verder op te delen. Juist concerns vanuit data management zijn een belangrijke drijfveer voor verschillende indelingen. Naast het voorbeeld dat hierboven is gegeven – opdeling naar artikelgroepen – is het bijvoorbeeld ook voorstelbaar dat er een opdeling plaatsvindt naar herkomst van de data. Bepaalde gegevenstypen kunnen vanuit verschillende (externe) bronnen afkomstig zijn. Stel, er is een externe data provider die alle consumentenprijzen kent van hetzelfde artikel in andere winkelketens. Vanuit datamanagement oogpunt is het dan nuttig een gegevensverzameling te definiëren die alleen die gegevenstypen bevat die de betreffende data provider aanlevert. Die gegevensverzameling kan dan bijvoorbeeld worden gebruikt om afspraken over de gegevenslevering vast te leggen. Zelfde gegevensgebied, andere gegevensverzameling.
Eenzelfde gegeven(stype) kan dus in meerdere gegevensverzamelingen voorkomen. In beginsel zou je kunnen zeggen dat er een oneindig aantal gegevensverzamelingen valt te definiëren. Ook hier is de kunst natuurlijk om de opdeling bewust te maken.
De opbouw van een data administratie met behulp van deze twee concepten kan zo dus stapsgewijs worden ingericht:
Gegevensmiddel
Het derde kernconcept is het gegevensmiddel. Een gegevensmiddel is een technisch middel waarin de data is opgeslagen. Het representeert de fysieke vastlegging van de data, een fysieke gegevensdrager dus. De omvang van een middel is hierbij niet relevant om middelen van elkaar te onderscheiden. Een gegevensmiddel kan dus zo klein zijn als een enkele databasekolom in een specifieke database instance of zo groot als een hele storage omgeving in de cloud.
‘Echte data’
Op het niveau van het gegevensmiddel komen we dus uit bij de ‘echte’ data. Het is ook op dit niveau waar data catalog- c.q. metadata management-tools waardevolle functionaliteit kunnen leveren. Tools als Alation, Enterprise Data Catalog (Informatica), Purview (Microsoft) of Collibra hebben connectoren naar platformen en technologieën als Azure, Snowflake, Oracle, SAP, AWS, Teradata, Tableau, Microstrategy etc. om op een intelligente manier de metadata uit te lezen over de data die in de betreffende bronnen is opgeslagen.
Hiermee wordt ook meteen duidelijk dat het fysieke niveau in beginsel enorm omvangrijk en gedetailleerd is. Om die enorme hoeveelheid metadata te benaderen, voorzien tools vaak in zoekfuncties.
Koppeling met gegevensgebied & -verzameling
Maar ook wordt duidelijk dat de hogere abstractieniveaus van gegevensverzameling en gegevensgebied nuttig en nodig zijn. Door samenhang tussen gegevensgebied, gegevensverzamelingen en de fysieke gegevensmiddelen vast te leggen, ontstaat een samenhangend en eenduidig beeld van de gegevenshuishouding.
Verdieping
Met begrip van het basis metamodel, behandelen we nu een aantal verfijningen op de uitwerking. Zoals in de eerder weergegeven figuur valt te zien, wordt een gegevensgebied opgedeeld in 1 of meerdere gegevensverzamelingen en komt iedere gegevensverzameling in 1 of meerdere gegevensmiddelen voor. De praktijk is helaas wat anders. Dat is weergegeven in onderstaande figuur:
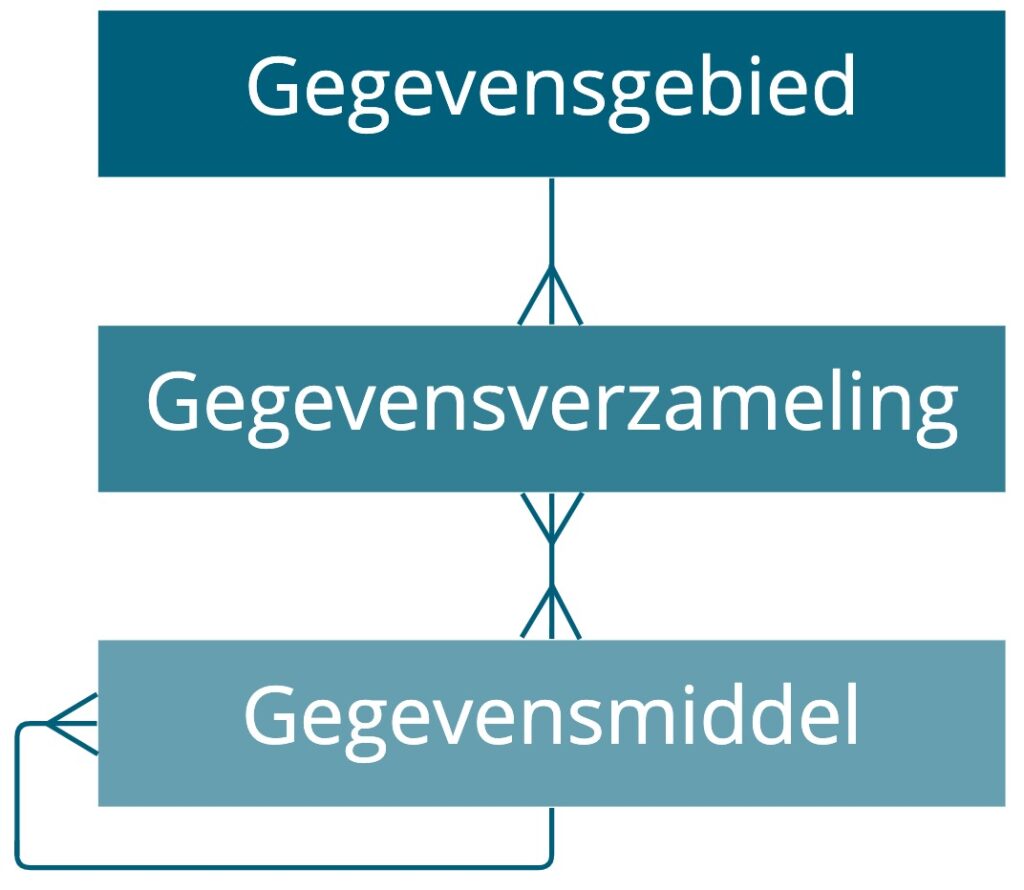
Wat opvalt is de veel-op-veel relatie tussen gegevensverzameling en gegevensmiddel. Een gegevensverzameling kan in meerdere gegevensmiddelen voorkomen (bijvoorbeeld een bestand, een bronsysteem en een afslag van dezelfde data in een data lake) maar ook: een gegevensmiddel kan gegevens bevatten uit meerdere gegevensverzamelingen (die ook uit een ander gegevensgebied komen…).
Verschillende detailniveaus
Hierbij moet worden opgemerkt dat het natuurlijk afhangt op welk niveau een gegevensmiddel wordt beschouwd. Wanneer een heel datawarehouse als middel wordt gezien, is het niet onlogisch dat er data in zit van verschillende gegevensverzamelingen en -gebieden. Maar in andere gevallen kan er sprake zijn van een onwenselijke situatie. Bijvoorbeeld wanneer door slecht ontwerp, replicatie, bewuste redundantie of andere ‘pragmatische’ oplossingen gegevens in 1 middel worden samengevoegd waar dat eigenlijk – vanuit een beheeroptiek – onwenselijk is.
Maak overlap inzichtelijk
Vanuit een administratief oogpunt is het vooral van belang om dit soort situaties inzichtelijk te maken. Zo ontstaat inzicht en kennis over hoe de gegevenshuishouding op zowel conceptueel / abstract als concreet niveau is ingedeeld. Dit inzicht helpt weer bij de uitvoering van data management.
Hiërarchie van gegevensmiddelen
Een tweede nuance die zichtbaar is in het model is de verwijzing van een gegevensmiddel naar zichzelf. Hiermee wordt de hiërarchie aangeduid die soms tussen middelen bestaat: een server bevat databases, die schema’s bevat, die views en tabellen bevat die weer kolommen bevatten. NB: in deze weergave wordt niet de lineage bedoeld tussen middelen (bijvoorbeeld data uit een datawarehouse tabel dient als bron voor een Tableau dashboard). Ook dat is een relatie tussen twee gegevensmiddelen maar betreft een ander concern en wordt niet bedoeld in bovengenoemde figuur.
Een interessante en relevante vraag is natuurlijk of al die niveaus en details allemaal nodig zijn. Wanneer data bronnen geautomatiseerd worden gecatalogiseerd door een tool krijg je al die details er als het ware gratis bij. Maar heb je die ook allemaal nodig? Die vraag en een aantal andere implementatie concerns bespreken we in het volgende hoofdstuk.
Implementatie concerns
Het hiervoor gepresenteerde metamodel biedt een stabiele basis om te beginnen met het vastleggen van metadata en stapsgewijs meer soorten metadata toe te voegen. Ter afsluiting bespreken we een aantal overwegingen bij het toepassen van het metamodel.
Drie beschouwingswijzen
Met het metamodel worden drie beschouwingswijzen van data geïntroduceerd. Voor metadata – informatie die we over data willen administreren – zal nu een keuze gemaakt moeten worden op welke beschouwingswijze van de data die metadata betrekking heeft. Neem het voorbeeld van het toekennen van een vertrouwelijkheidsclassificatie als ‘Intern’, ‘Publiek’ of ‘Vertrouwelijk’ bijvoorbeeld. Aangenomen dat het concept ‘vertrouwelijkheidsclassificatie’ eenduidig kan worden gedefinieerd, is de vraag op welk niveau die classificatie wordt vastgelegd: op het niveau van een gegevensgebied, -verzameling of -middel?
Voor ieder toe te voegen concept – ieder toe te voegen soort metadata – zal deze vraag opnieuw moeten worden gesteld. En voor de goede orde: op dit soort vragen bestaat ook niet één goed of fout antwoord. Zo is het in het bovengenoemde voorbeeld prima voorstelbaar dat vertrouwelijkheidsclassificatie op zowel niveau van een gegevensverzameling als -middel wordt vastgelegd. Direct komt dan de vraag naar boven hoe die twee niveau’s zich tot elkaar verhouden. Stel een gegevensverzameling bestaat uit drie gegevensmiddelen en die middelen krijgen de classificatie vertrouwelijk, vertrouwelijk en zeer vertrouwelijk toegekend? Welk classificatie krijgt de verzameling dan? Zo helpt het metamodel om dit soort discussies te voeren en afspraken te maken wat de betekenis van metadata is en welke business rules erop van toepassing zijn.
Think big, act small
Het metamodel leent zich uitstekend om klein te beginnen en iteratief te laten groeien. Het model kan gevuld worden voor 1 specifieke use-case en uitgebreid worden met alleen die soorten metadata die voor een specifiek vraagstuk nodig zijn. Uiteraard is het wel van belang die uitbreiding weloverwogen te doen: ieder nieuwe concept c.q. type metadata moet goed gedefinieerd worden alvorens deze wordt toegevoegd aan het metamodel.
Onderscheid tussen data en systemen
Eerder hebben we aangegeven dat het belangrijk is onderscheid te maken tussen de beschouwing van de data en systemen. We kunnen dat nu scherper illustreren aan de hand van het metamodel en doen dat aan de hand van twee voorbeelden.
Veel organisaties kennen een analyse-, data science-, analytics- of BI-omgeving die met termen als ‘Data Lab’, ‘Data Hub’, ‘Datawarehouse’, ‘Managed Data Platform’ e.d. wordt aangeduid. Wat hopelijk duidelijk is, is dat dit soort aanduidingen abstracte termen zijn: je kan niet naar de IT-infrastructuur wijzen en zeggen: díe component is de Data Hub. Anders gezegd: je zou kunnen stellen dat – laten we de term ‘Data Hub’ even verder in dit voorbeeld gebruiken – de Data Hub als systeem beschouwd zou kunnen worden die data diensten levert. De Data Hub maakt gebruikt van c.q. wordt gerealiseerd door verschillende gegevensmiddelen. Waarschijnlijk is er sprake van een set aan middelen – bijvoorbeeld AWS storage accounts, een Snowflake instance, een aantal Azure Synapse databases – die samen de Data Hub vormen. Het metamodel kan nu worden uitgebreid met een apart concept ‘Systeem’ waarin alle systemen / applicaties / toepassingen kunnen worden geadministreerd. vervolgens kan worden vastgelegd van welke middelen ieder systeem gebruik maakt. Op dezelfde manier kunnen verschillende dashboards of rapportages als afzonderlijke ‘systemen’ worden vastgelegd. Het ‘Verkoop-dashboard’ is bijvoorbeeld een (abstracte) term om een of meerdere concrete Tableau-dashboards aan te duiden (gegevensmiddelen dus). Die Tableau-dashboards maken op hun beurt weer gebruik van onderliggende gegevensmiddelen (files, databases waar de data aan ontleend wordt).
Op deze manier is het dus mogelijk om een aparte beschouwing van het concept van een systeem c.q. applicatie te hanteren én de gegevensmiddelen waar zo’n systeem gebruik van maakt.
Deze beschouwingswijze geldt ook voor de OLTP-wereld alleen lopen daar deze twee beschouwingswijzen vaak veel meer door elkaar heen. Neem een willekeurig ERP- of softwarepakket. Het pakket als geheel kan als systeem worden gezien maar de afzonderlijke modules – bijvoorbeeld relatieadministratie, contracten, boekhouding etc – kunnen ook als losse applicaties worden beschouwd. Tegelijkertijd kan het betreffende pakket ook als gegevensmiddel worden gezien. Dit soort software gaat vaak integraal gepaard met zijn eigen gegevensopslag; het pakket is daarmee ook een system of record. Ondanks deze verwevenheid helpt de afzonderlijke beschouwing van systeem en data om deze concerns uit elkaar te houden. Zo kan ‘het CRM-systeem’ betrekking hebben op specifieke functionaliteit (systeem-perspectief) maar ook de data die ermee wordt beheerd (gegevensmiddel-perspectief). Door dit in het metamodel van elkaar te onderscheiden en apart te administreren ontstaat inzicht. Dat komt het data management vervolgens ten goede.
Data Catalog Accelerator programma
Het opstellen van een effectief en efficiënt metamodel is onderdeel van het Data Catalog Accelerator programma. Door middel van een methodische aanpak realiseren we samen met de opdrachtgevende organisatie binnen twee tot drie maanden een klantspecifiek metamodel. We implementeren vervolgens een concrete oplossing voor een actuele use-case en ontwikkelen samen een plan voor het verder structureel inzetten van een data catalog of metadata-management oplossing.
Ben je nieuwsgierig geworden naar wat een metamodel zou kunnen betekenen voor jouw organisatie? Of wil je gewoon meer informatie hebben over het Deltiq Data Catalog Accelerator programma? Neem dan gerust contact met ons op!
Referenties
- van der Sanden, W., & Sturm, B (1997). Informatiearchitectuur – de infrastructurele benadering. Panfox, Rosmalen, The Netherlands, EU
- Wieringa, R. J. (2014). Design science methodology for information systems and software engineering. Springer